简单介绍
JDK1.4之后引入NIO,允许java直接使用native函数申请使用本机内存。然后通过存储在JVM堆中的DirectByteBuffer对象来作为这块内存的引用来进行操作
不属于JVM运行时的数据区域,即和堆没啥直接关系,也就不受堆内存大小限制。
不受堆内存大小限制。具体之前的一篇文章中提到过java进程的内存组成,可以参见JVM xms和Linux Top RES的关系
直接内存在分配和释放上成本更大。原因在于 直接内存申请时,需要调用本地方法完成系统调用。 而堆内存的申请相对于直接内存而言成本会低,原因在于堆内存是JVM预先申请,堆内存在使用时,只需要从已分配的内存空间里获取即可,不需要再走系统调用了。
但在读写上会很占优势。
有啥用
防止数据在Java堆和native堆之间拷贝带来的性能损耗,在频繁IO操作(比如网络并发场景)或者复制很大文件时比较有用。 (可以看下官方堆ByteBuffer的介绍)
It is therefore recommended that direct buffers be allocated primarily for large, long-lived buffers that are subject to the underlying system's native I/O operations.
官方的一个介绍

如何申请直接内存
使用ByteBuffer
使用ByteBuffer.allocateDirect() 即可申请直接内存。比如,下面代码可申请300M的直接内存。
//分配300M空间
int ONE_MB = 1024 * 1024 ;
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(300 * ONE_MB);
使用VisualVm可以查看直接内存的使用情况,如下
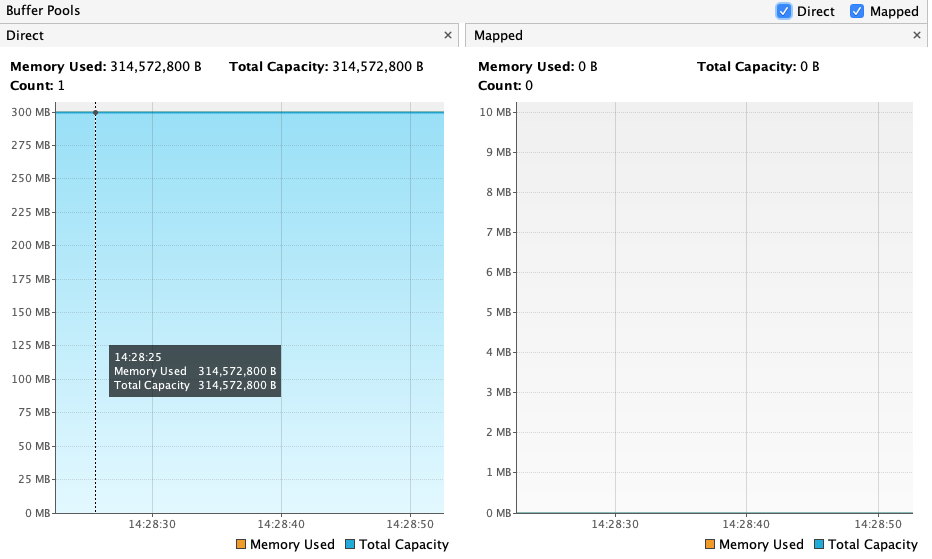
PS:
VisualVM查看直接内存,需要安装插件VisualVM-BufferMonitor
使用Unsafe
另外一种办法是使用UnSafe来申请直接内存。但 谨慎 使用。使用UnSafe时,JVM无法干预内存分配和回收,使用之后需要手动释放,否则将可能出现内存泄露。
UnSafe直接申请的内存,是无法被JVM监控到的,所以相应的一些管理软件无法监测到这部分内存占用,比如上面所提到的VisualVM就无法检测到。
代码:
try {
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe)f.get(null);
long address = unsafe.allocateMemory(150 * ONE_MB);
unsafe.setMemory(address, 150 * ONE_MB, (byte)0);
System.out.println("使用Unsafe申请直接内存,大小150M");
} catch (Exception e) {
e.printStackTrace();
}
如上代码,执行后,我们使用VisualVM监测直接内存,发现是看不到的。
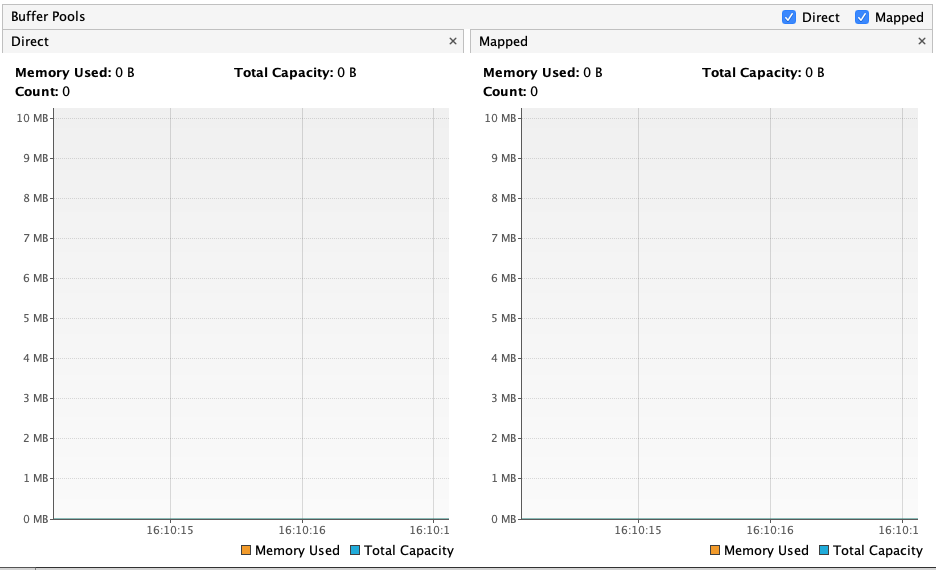
但查看当前进程的虚拟内存占用是有150M的占用的。 (我使用的是Mac的top看的,Linux可以用top查看(未实际验证))

另外:
unsafe.allocateMemory 只是申请了一块内存地址,并未实际占用。 所以如果我们把上面代码中的unsafe.setMemory(address, 150 * ONE_MB, (byte)0); 去掉之后,top看当前java进程的实际内存占用只有9M。并未有150M的占用。
PS:
Unsafe无法被直接调用,需要通过反射的方式来做。 从Unsafe的getUnsafe()方法可以看出,非系统classloader则会被抛出安全异常
//UnSafe的getUnsafe方法
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
如何限制直接内存大小
使用ByteBuffer申请直接内存时,可以通过 -XX:MaxDirectMemorySize设置直接内存大小
使用Unsafe直接申请时,参数-XX:MaxDirectMemorySiz 无效。 受限于机器内存。
直接内存GC
-
FullGC可回收直接内存。
前提是使用ByteBuffer来申请,如果直接使用Unsafe申请的话,是不可以回收的。
Unsafe下申请的内存,需要通过unsafe.freeMemory来手动释放。
注: 除非必须,不要直接使用Unsafe申请使用内存。因为不受JVM管理,无法自动回收内存,容易出现内存泄露。
System.gc()可告知JVM发起FullGC,一般情况下是能触发FullGc的。所以System.gc()大部分时间下是能触发直接内存回收。之前提到过的jcmd,也可以通过命令的方式手动触发fullgc。具体可以参见Jcmd介绍
-
也可以是用Cleaner.clean()手动释放(不推荐)
使用
((DirectBuffer)buffer).cleaner().clean();可手动释放。但JVM的好处就在于不需要开发人员过多关心内存的申请释放,所以不建议使用。
PS:
这篇文章写的挺详细,可以看下 : https://blog.csdn.net/Big_Blogger/article/details/77654240
测试
申请性能测试对比(堆内存和直接内存对比)
测试代码:
public class DirectMemoryDemo {
private static final int ONE_B = 1;
public static void main(String[] args) {
int initTestTimes = 5000;
for (int i = 1; i < 50; i++){
int testTimes = i * initTestTimes;
CostVo vo = testCost(testTimes);
System.out.println(testTimes + "," + vo.toString());
}
}
private static CostVo testCost(int testTimes){
//测试申请性能
//堆内存申请
long startTime = System.currentTimeMillis();
for (int i =0; i < testTimes; i++){
ByteBuffer.allocate(ONE_B);
}
long heapCost = System.currentTimeMillis() - startTime;
//直接内存申请
startTime = System.currentTimeMillis();
for (int i =0; i < testTimes; i++){
ByteBuffer.allocateDirect(ONE_B);
}
long directCost = System.currentTimeMillis() - startTime;
CostVo vo = new CostVo(heapCost, directCost);
return vo;
}
}
class CostVo{
private long heapCost ;
private long directCost;
public CostVo(long heapCost, long directCost) {
this.heapCost = heapCost;
this.directCost = directCost;
}
public long getHeapCost() {
return heapCost;
}
public void setHeapCost(long heapCost) {
this.heapCost = heapCost;
}
public long getDirectCost() {
return directCost;
}
public void setDirectCost(long directCost) {
this.directCost = directCost;
}
@Override
public String toString() {
return heapCost + "," + directCost ;
}
}
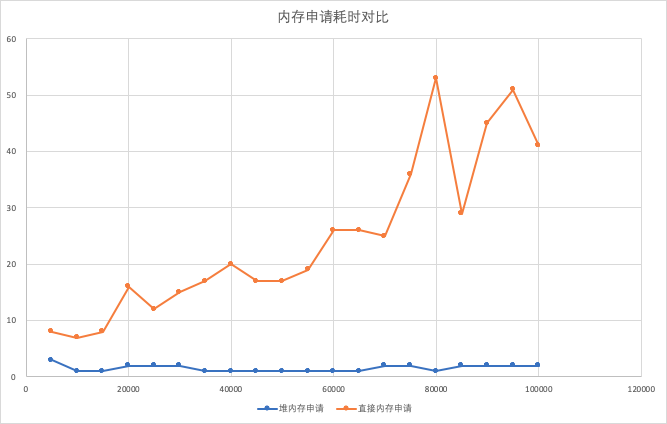
能够看出来,直接内存申请耗时远高于堆内存申请。
读写性能对比(堆内存和直接内存对比)
代码
/**
* 测试读写性能
* @param testTimes
* @return
*/
private static CostVo testWriteCost(int testTimes){
//申请堆内存空间
ByteBuffer heapBuffer = ByteBuffer.allocate(ONE_B * 4 * testTimes);
//堆内存写
long heapCost = getReadWriteCost(heapBuffer, testTimes);
//申请直接内存空间
ByteBuffer directBuffer = ByteBuffer.allocateDirect(ONE_B * 4 * testTimes);
//直接内存写
long directCost = getReadWriteCost(directBuffer, testTimes);
CostVo vo = new CostVo(heapCost, directCost);
return vo;
}
private static long getReadWriteCost(ByteBuffer byteBuffer, int testTimes){
long startTime = System.currentTimeMillis();
//写
for (int i =0; i < testTimes; i++){
byteBuffer.putChar('a');
}
//将缓冲区翻转
byteBuffer.flip();
//读
for (int i = 0; i < testTimes; i++){
byteBuffer.getChar(i);
}
long cost = System.currentTimeMillis() - startTime;
return cost;
}
结果显示,直接内存读写性能优于堆内存读写。
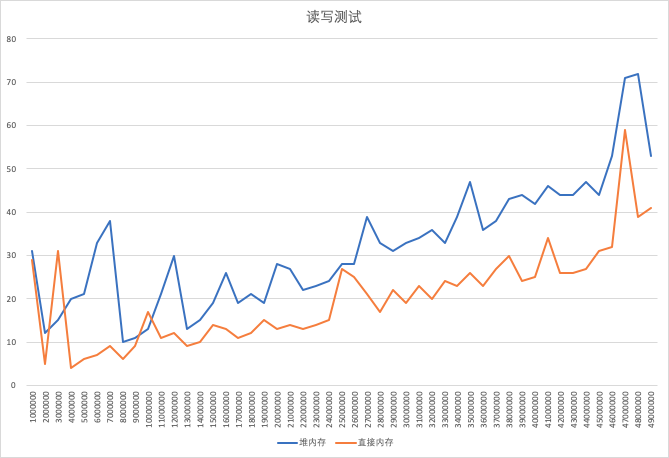
前面提到直接内存我们主要用来IO操作频繁或者大文件复制的情况,所以我们改进下上面的代码,增加IO部分的测试。加入以下代码:
/**
* 测试读写性能,有IO
*
* @return
*/
private static CostVo testWriteCostWithIO(File f ) {
//申请堆内存空间
ByteBuffer heapBuffer = ByteBuffer.allocate(ONE_MB);
//堆内存读写
long heapCost = getReadWriteCostWithIO(f, heapBuffer);
//申请直接内存空间
ByteBuffer directBuffer = ByteBuffer.allocateDirect(ONE_MB);
//直接内存读写
long directCost = getReadWriteCostWithIO(f, directBuffer);
CostVo vo = new CostVo(heapCost, directCost);
return vo;
}
/**
* 读写IO测试
* @param f
* @param byteBuffer
* @return
*/
private static long getReadWriteCostWithIO(File f, ByteBuffer byteBuffer) {
File fout = new File(DEFAULT_PATH + new Random().nextInt() +"out_.txt");
FileInputStream fis = null;
FileOutputStream fos = null;
long startTime = System.currentTimeMillis();
try {
//读文件
fis = new FileInputStream(f);
FileChannel finChanel = fis.getChannel();
fos = new FileOutputStream(fout);
FileChannel channel = fos.getChannel();
int length = -1;
while((length=finChanel.read(byteBuffer)) != -1 ){
finChanel.read(byteBuffer);
byteBuffer.flip();
//写文件
channel.write(byteBuffer);
byteBuffer.clear();
}
finChanel.close();
channel.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (fis != null ){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
long cost = System.currentTimeMillis() - startTime;
return cost;
}
//主测试函数
public static void main(String[] args) {
for (int i = 1; i < 10; i++) {
CostVo writeCost = testWriteCostWithIO(new File("/opt/wf/tmp/test.mobi"));
System.out.println(i + " " + writeCost.toString());
}
}
执行之后,发现性能测试如下图
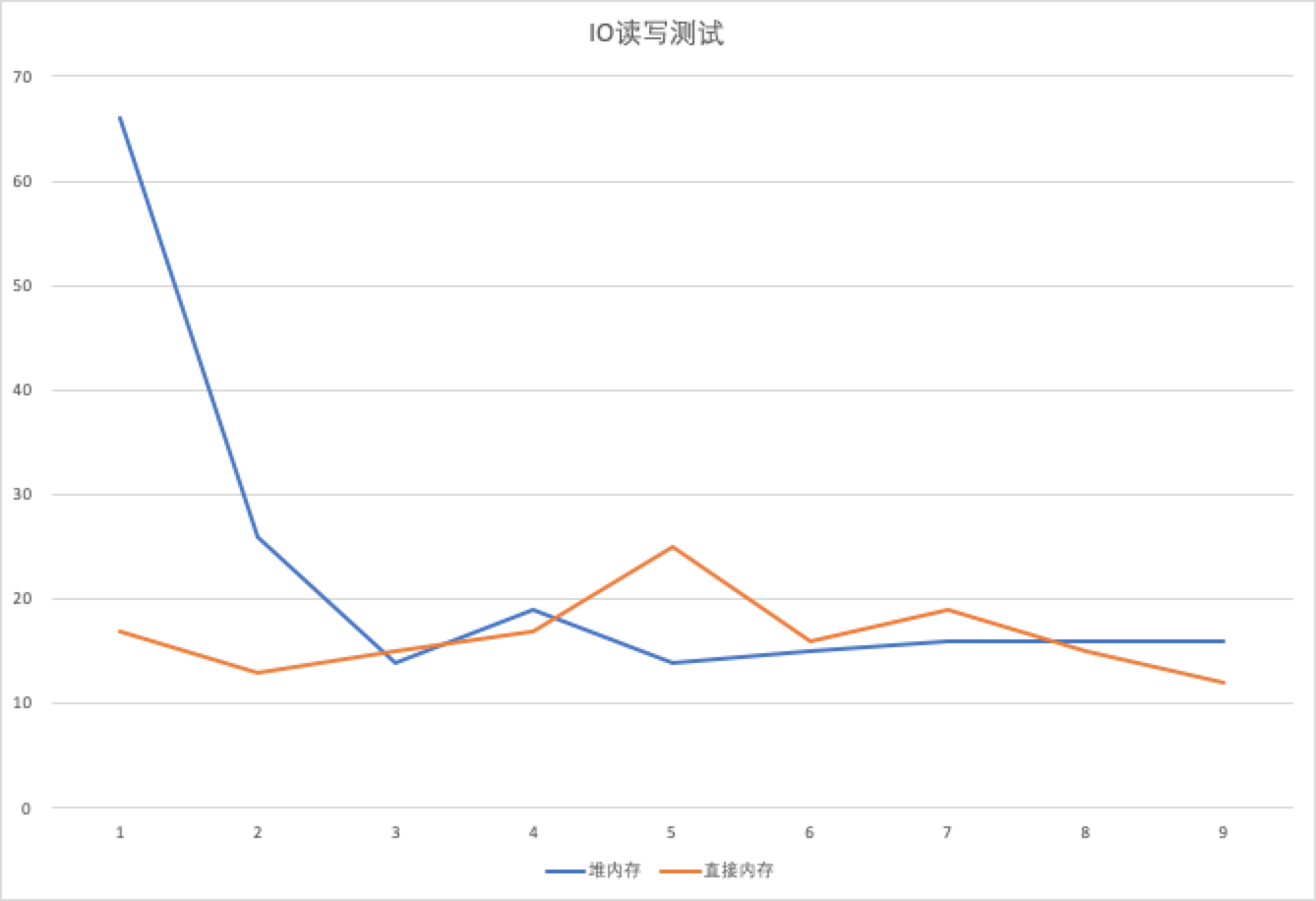
可以看出,堆内存在最开始的时候耗时是远大于直接内存的。
但是,测试结果 并没有完全符合预期 ,因为第一次之后,堆内存性能基本已经和直接内存相当了。
我们看下核心代码,拷贝读写过程,主要在finChanel.read(byteBuffer);这里。 我们查看FileChanel.read(ByteBuffer buffer)方法,具体的实现类在FileChanelImpl类里。
代码如下图
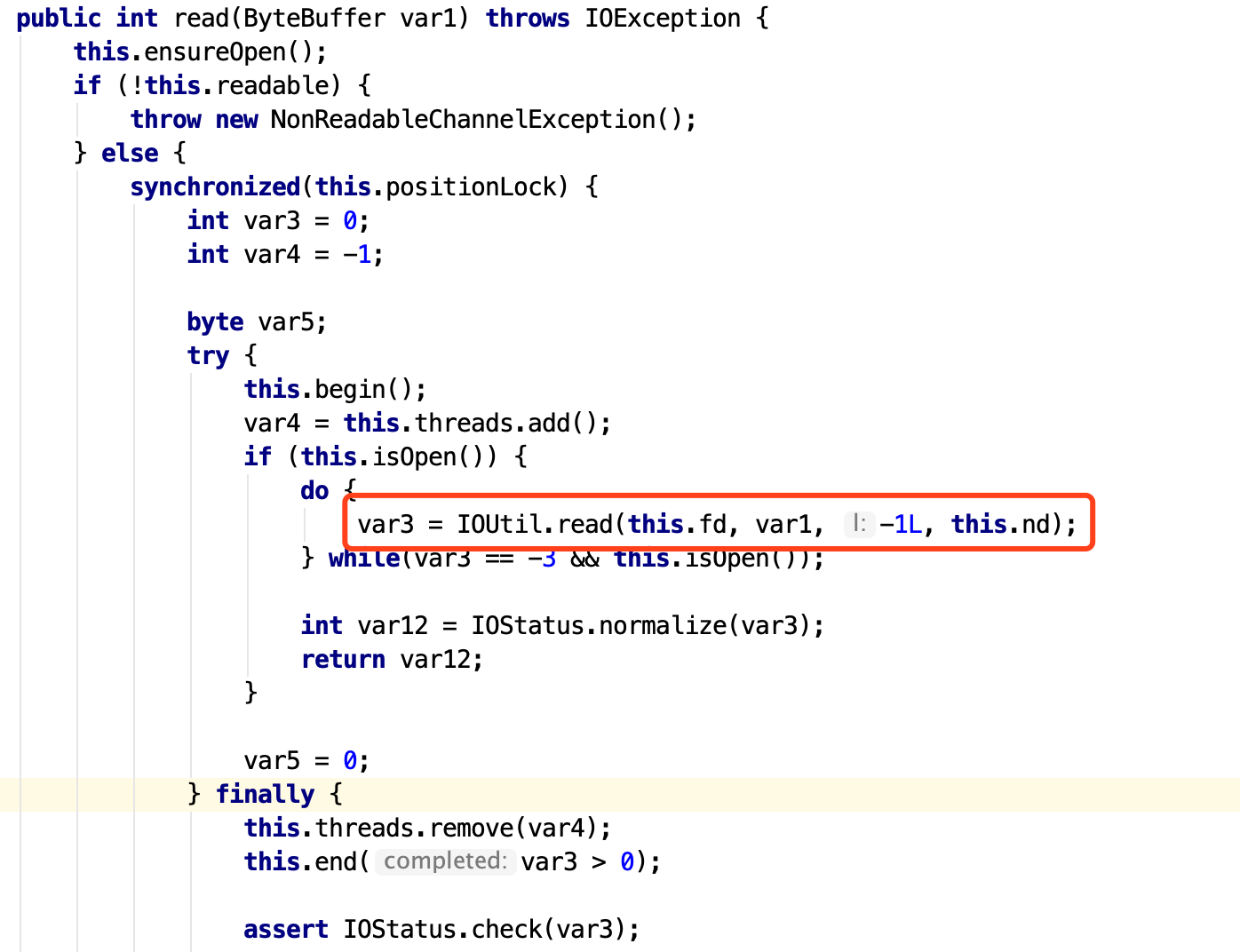
最关键的代码在IOUtil.read()方法。
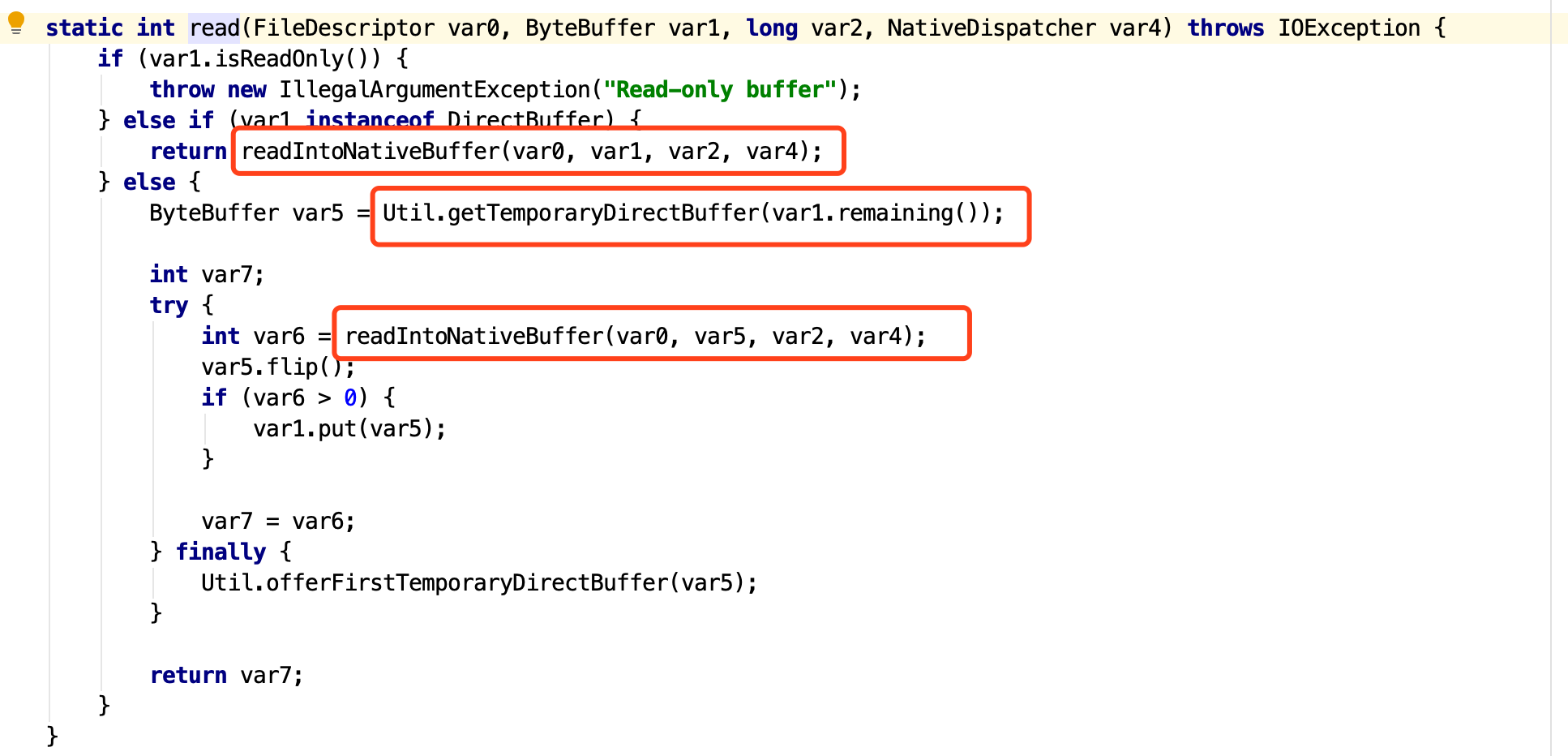
这段代码的主要逻辑是:
- 如果是
DirectBuffer,那么直接拷贝到NativeBuffer中去。 - 如果不是
DirectBuffer,那么就先创建一个临时的DirectBuffer,然后再将数据拷贝到NativeBuffer中去。
所以相对而言,如果是DirectBuffer,那么就可以省掉一步创建DirectBuffer的过程。可想而知,性能肯定会高一些。
接着看Util.getTemporaryDirectBuffer这个方法,这个是在HeapBuffer的情况下,去申请临时的DirectBuffer的方法。
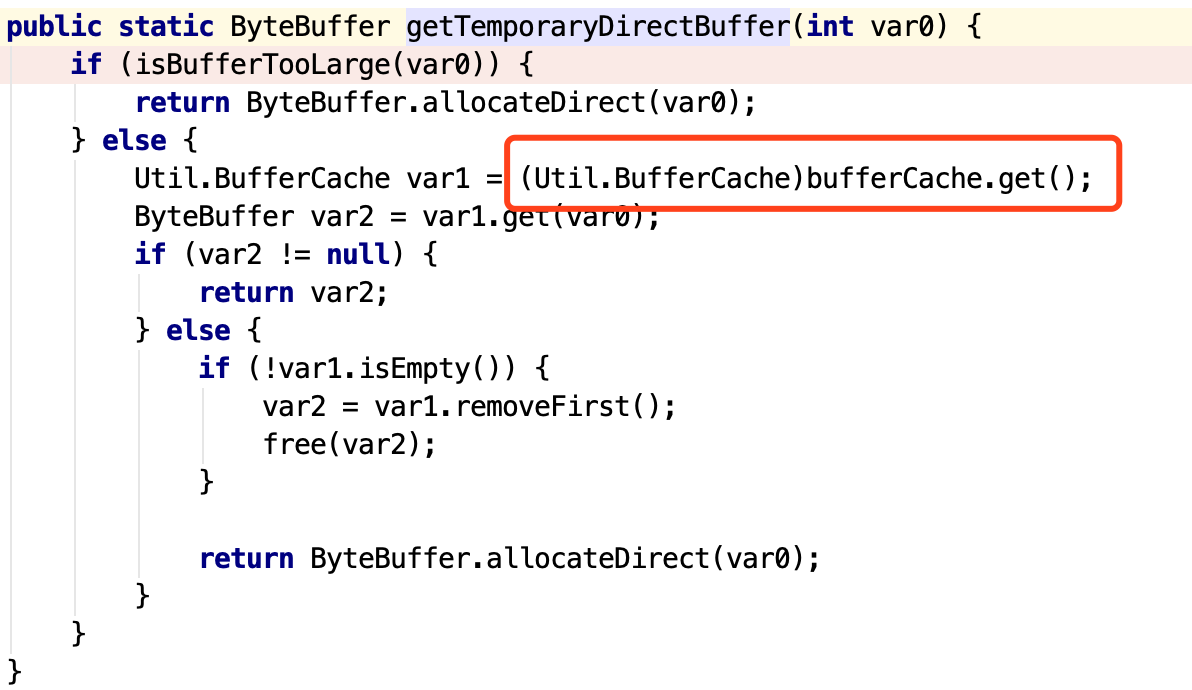
第一句话isBufferTooLarge基本很难达到条件,所以基本都走了下面的else分支,基本逻辑是,先从Cache中取缓存中的DirectBuffer,如果有的话,直接返回,如果没有的话,就申请一个新的直接缓存。
有兴趣的话,可以继续跟一下bufferCache.get()方法,里面的逻辑就是如何从缓存中获取到空闲的DirectBuffer供程序调用。
但上述代码中,只是说从Cache中获取DirectBuffer,但没有将申请到的DirectBuffer放入Cache的过程。这块在IOUtils.read()方法的finally块里有。
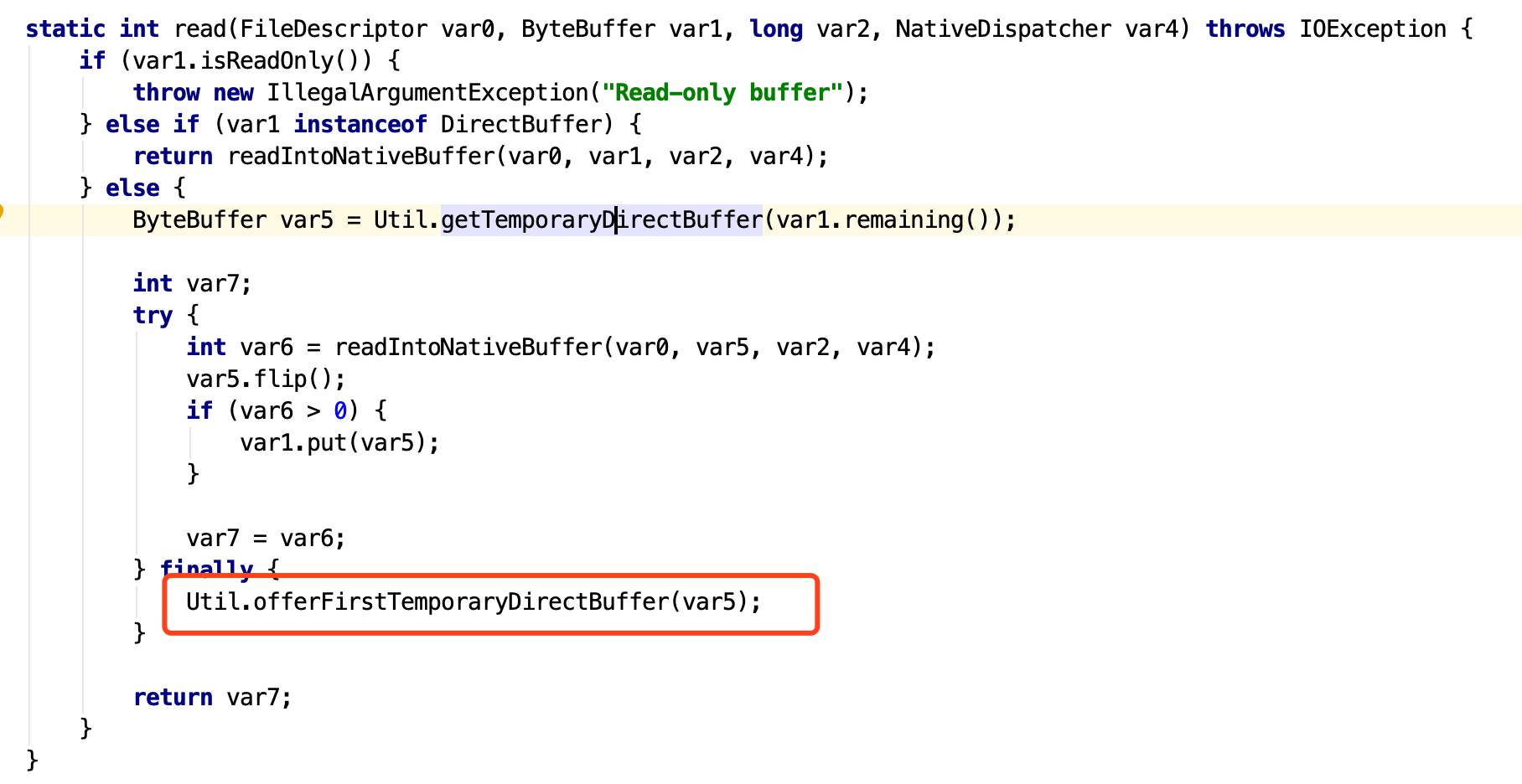
具体看下代码:
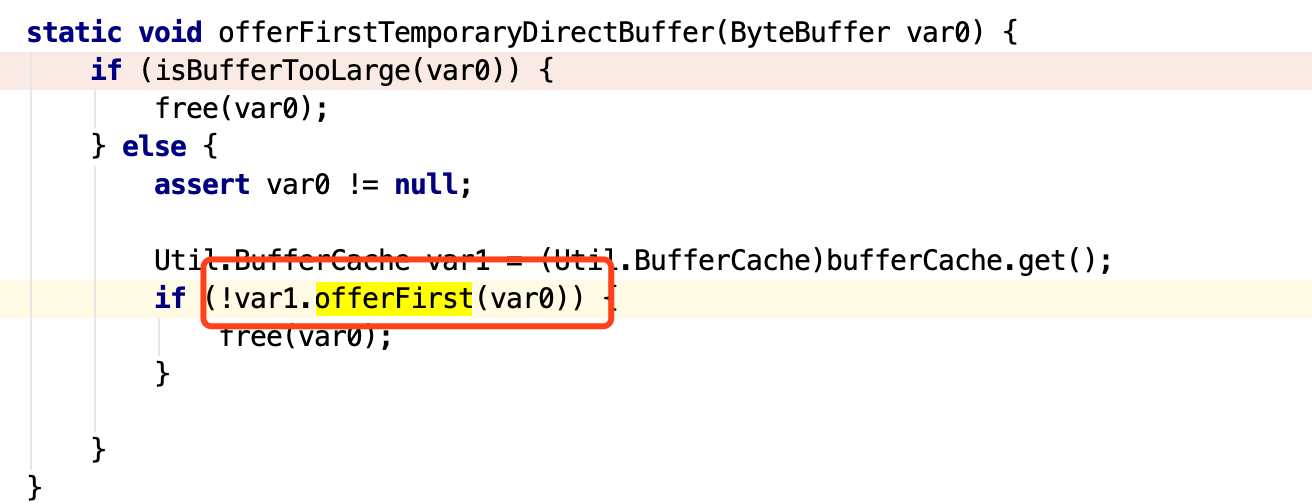
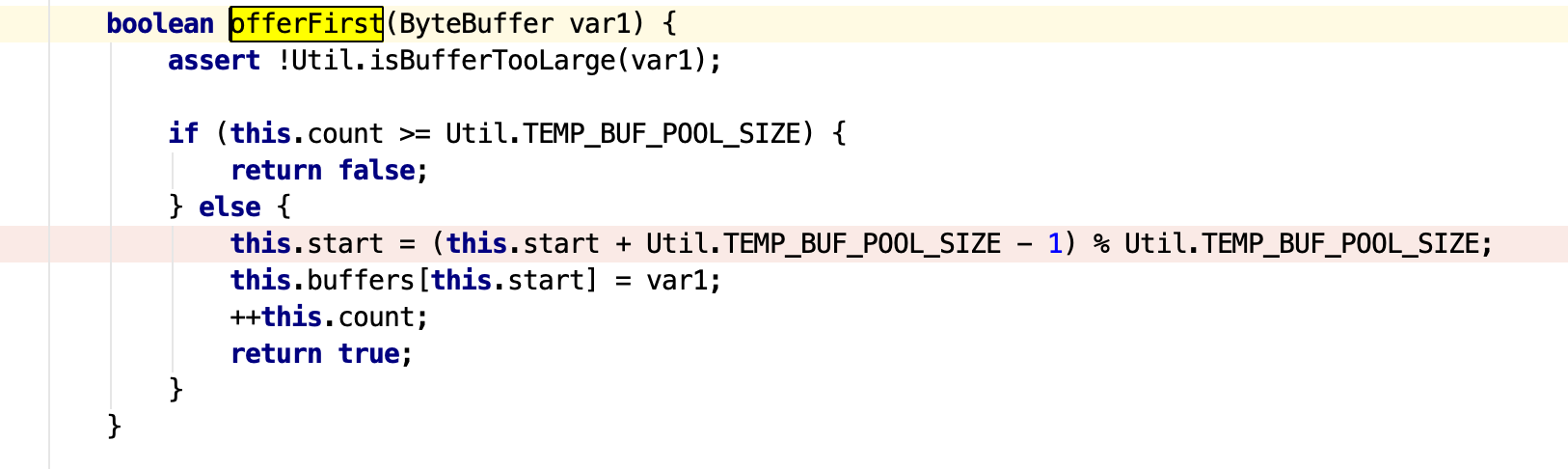
这块将会把申请到的DirectBuffer放到Cache里面 。
所以现在基本上也就能解释了,为什么首次的时候DirectBuffer性能优于HeapBuffer。但后面就没什么差距了。 因为后面都走了缓存的DirectBuffer。实际上就相当于是DirectBuffer了。 性能自然差距不大。
write方法和这个类似。 不过多分析。
从上面基本上可以得到的一个结论是,使用HeapByteBuffer时,数据流转是: HeapByteBuffer-->DirectByteBuffer-->PageCache-->磁盘 ,所以理论上HeapByteBuffer的性能低于DirectByteBuffer。
另外,因为是用HeapByteBuffer时会创建临时DirectByteBuffer,所以当多线程的情况下(或者实际工程里)很可能出现随着HeapByteBuffer增大的同时,发现DirectByteBuffer也在增大。这块需要注意下。
PS1:
HeapByteBuffer是HeapBuffer的实现类。DirectByteBuffer是DirectBuffer的实现类。
PS2:
Java中的IO是Buffer IO,也叫做Standard IO,操作系统会将IO的数据缓存到PageCache中,之后才会被应用程序使用到。
补充
为什么数据要在Java堆和Native堆之间来回拷贝?
前面提到说直接内存的用处是为了减少Java堆内存和native堆之间来回拷贝,但是为什么需要将数据先从堆内存拷贝到直接内存,再写入到IO。而不是直接将数据写入到直接内存?
主要有几个原因:
-
ByteBuffer底层是数组实现
-
操作系统操作IO时,倾向于读取一块连续(一整块)的内存来进行操作,因为IO太慢了。
-
如果把堆里面的byte[]对象引用给到native代码,就要求byte[]对象不能被移动。但目前的GC除了CMS外,因为GC的原因,都会移动对象。如果要保证byte[]对象不能被移动,那么就得暂停GC,但暂停GC就可能导致堆内存OOM。
-
所以,现在的JDK先将堆内存的byte[]对象拷贝到直接内存,然后将直接内存中的byte[]引用给到native代码。因为直接内存不受JVM的GC影响(FullGC除外),所以就不影响GC。但这个前提是假定 从堆拷贝到直接内存的时间很小,并且IO操作很慢(实际也是这样的)
PS:
更详细的解释,可以参考R大等人的解释:
Java NIO中,关于DirectBuffer,HeapBuffer的疑问? - RednaxelaFX的回答 - 知乎
https://www.zhihu.com/question/57374068/answer/152691891
Java NIO中,关于DirectBuffer,HeapBuffer的疑问? - 曾泽堂的回答 - 知乎
https://www.zhihu.com/question/57374068/answer/153398427阿里徐靖峰的一篇关于堆外内存监控的解释:https://www.cnkirito.moe/nio-buffer-recycle/
参考
https://stackoverflow.com/questions/18913001/when-to-use-array-buffer-or-direct-buffer
https://www.zhihu.com/question/284750570
https://www.zhihu.com/question/60892134
https://blog.csdn.net/Alpha_Paser/article/details/82532903
https://www.csdn.net/gather_2c/MtjaIg3sNjkwMi1ibG9n.html
https://cloud.tencent.com/developer/article/1022259
https://segmentfault.com/a/1190000021471509
https://www.javazhiyin.com/44196.html
https://mritd.me/2016/03/22/Java-%E5%86%85%E5%AD%98%E4%B9%8B%E7%9B%B4%E6%8E%A5%E5%86%85%E5%AD%98/
https://juejin.im/post/5cb48201f265da03b0515294
http://ibm.com/developerworks/library/j-nativememory-linux/index.html
https://blog.csdn.net/Big_Blogger/article/details/77654240
TODO:
-
零拷贝
-
一系列文章:
https://juejin.im/post/5c1b2787f265da616d542477
https://juejin.im/post/5c1b285de51d452f6028a98d
https://juejin.im/post/5c1b537f6fb9a04a0821a3cd
https://juejin.im/post/5c1b546b51882545e24f1228
https://juejin.im/post/5c1b54d8f265da611510c143
https://juejin.im/post/5c1b5535e51d450c2c0807b7
-
-
NIO
-
MMAP
-
GC
