缓存穿透
现象:
正常情况下,我们用缓存的目的是为了让请求尽量少的到达DB,减少对DB的压力。
但是有一种情况是,某个请求的数据,在DB中压根不存在, 也就意味着在缓存中肯定也不存在,那么这个请求就一定会落到DB上, 这种现象称作 缓存穿透。
影响:
这种请求少的情况下,没什么问题,对DB的压力不大。但是如果有用户恶意用一批压根不在DB中的数据去请求系统,就会导致请求全部压力到DB上,这种情况下,就很可能导致DB宕机,进而引起整个系统的雪崩。
解决:
一种是缓存空对象。
一般情况下,我们的缓存中只会保存数据库中存在的数据。所以,当我们查询一个数据库中不存在的数据时,缓存一定不会命中,就会导致请求最终落到DB上。
所以,我们可以把数据库中查询不到的数据,同样也缓存在DB中,缓存成一个空值。 这样查询是,发现缓存中的数据为空,就直接返回,而不在请求DB。 从而减少缓存穿透的情况。
但需要注意的是, 数据可能不一定一直在DB中不存在,所以,相应的缓存的空值,需要设定过期时间。
一种是使用布隆过滤器。
缓存空对象的场景比较适合与空值相对有限,并且重复访问较多的情况。 如果空值很分散,数据很多,并且重复访问少的话, 缓存空对象,一方面会导致内存变大,另外一方面会导致缓存的命中率不高,使用效率不高。
所以,如果是空值分散,数量不可控,且重复访问较少 的时候,可以考虑使用布隆过滤器。比如,我们前面提到的恶意访问,用一批不存在的数据来请求系统。
布隆过滤器中存储所有可能存在的数据Key值,系统请求时,先判断是否在布隆过滤器中能查询到,如果能查询到,则再查询缓存, 如果查询不到,则直接返回。不再请求缓存和DB,从而减少DB层压力。
大概的访问流程如下:
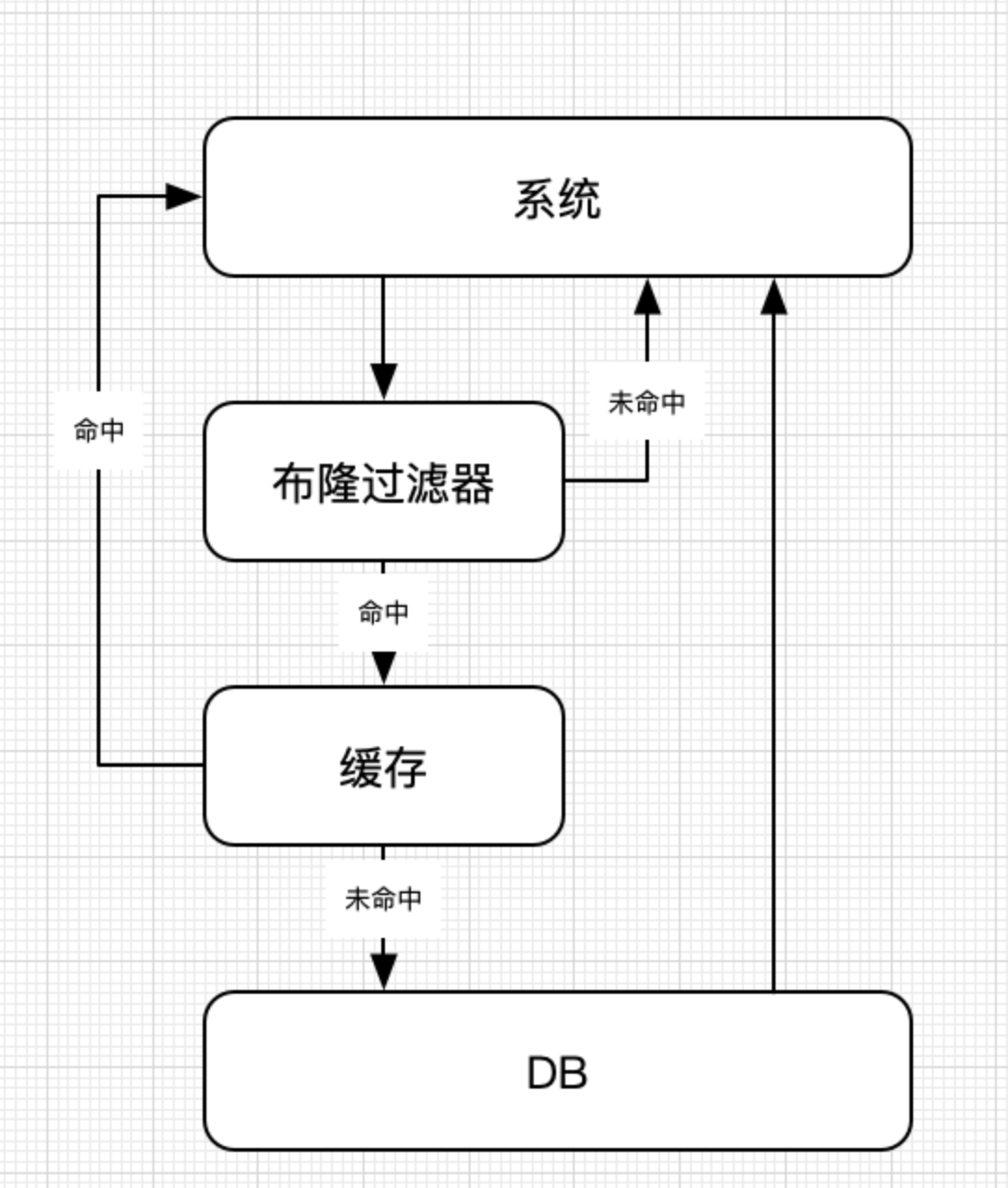
布隆过滤器可以选择使用本地版本的,也可以选择使用分布式版本的。 本地版本的需要考虑数据同步的问题。 分布式版本的,现在有人在Redis上实现了布隆过滤器,具体可以参考:https://github.com/erikdubbelboer/Redis-Lua-scaling-bloom-filter
本地版本的,可以使用Guava提供的BloomFilter 具体参见:https://github.com/google/guava/wiki/HashingExplained#bloomfilter
| 方案 | 使用场景 | 优缺点 |
|---|---|---|
| 缓存空对象 | 1、空值数量有限,且重复访问次数相对较多(命中次数多) 2、数据实时性要求高,数据变化较频繁(指数据后期可能非空) | 1、代码较简单 2、需要额外的内存空间 3、因缓存存在有效期,所以存在数据和DB不一致的情况 |
| 布隆过滤器 | 1、空值数量较多,且命中次数较少 2、数据实时性要求不高,数据变化较少 | 1、代码比较麻烦,维护成本相对较高 2、内存占用空间小,如果放到本地,还会降低对缓存的请求压力。 3、存在误算的情况,即存在布隆过滤器显示存在,可能在DB中不存在的情况(误算率一般很低,可以自行设定) |
备注:上面提到的命中次数多少,是相对于空值这个数据集而言,而非全量数据。 如果空值的命中次数大于非空值的命中次数,说明缓存设计存在问题, 命中率也不会高。
缓存击穿
现象:
缓存中的key值存在过期时间时,如果刚好过期,此时又有请求过来,则缓存中查询不到,便会将请求打到后端的DB上去。 如果当前的key值非热点key值倒还好,对后端DB压力不大, 但如果当前key值属于热点key值,在失效的那一刻,就可能导致大量的请求打到后端DB上去,可能导致DB压力过大产生问题。
另外一种,是缓存中,一批数据刚好同时过期,导致请求缓存中命不中,转而请求到DB上去,导致DB压力瞬间变大。
这两种情况,叫做缓存击穿。
影响:
并发请求大的时候,会导致后端DB压力瞬间变大,严重时可能会导致DB宕机。
解决办法:
缓存击穿需要解决的点,在于数据回源。 并发大的时候,导致同时回源的请求过多,但实际上,可能只需要一次DB请求即可,而不需要所有的请求都走一遍数据库,再写回到缓存中。
所以相应的解决办法也相对比较明确,要么控制回源数量,只允许一个请求回源,其余请求等待。 要么没有回源,把回源这个操作避免掉,也就不会存在缓存击穿的问题了。
1、回源时加互斥锁,只允许一个请求去请求DB,然后写回缓存,其余并发线程等待直到超时或者拿到锁释放拿到数据。
大概的流程图如下:
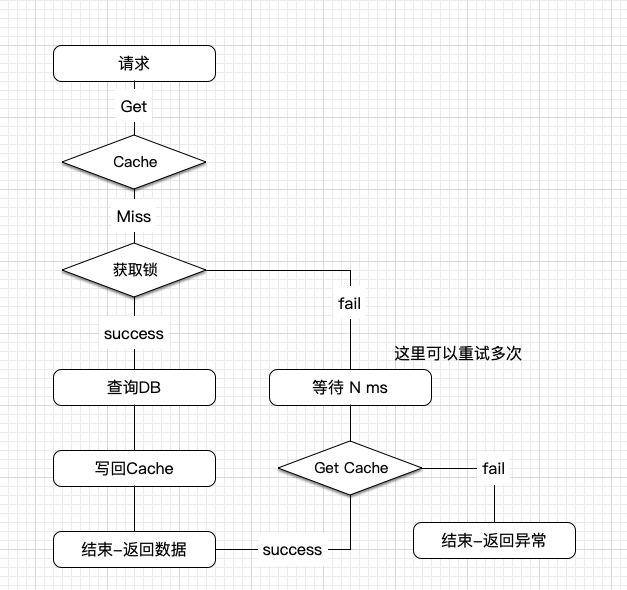
相应的伪代码如下(未获取到锁的仅重试一次,根据业务需要可以重试多次)
public String get(String key){
String val = redis.get(key);
if (null == val){
//缓存中不存在,防止并发时多线程回源,此处加锁
//redis3.0之后加锁可以通过set ex nx实现,之前版本需要使用setnx及expire来实现分布式锁
String mutexKey = "mutex:key_" + key;
//锁的值为 lock 字符串,过期时间10s
if (redis.set(mutexKey, "lock", new SetParams().ex(10).nx())){
//获取锁成功,则加载DB数据
String dbData = Dbhelper.get(key);
redis.set(key, dbData)
return dbData;
}else {
//休息50ms,再次获取
TimeUnit.MILLSECONDS.sleep(50);
String data = redis.get(key);
//TODO 这里可以判断data是否为空,为空则可抛出异常,让上层判断。
return data;
}
}
return val;
}
2、避免回源。
这种极端一点的做法是缓存不设置过期时间,这样的话,缓存不失效,也就意味着不需要查询DB了,也就不存在缓存击穿的问题。 但这样带来的问题是内存占用会越来越大,并且可能导致DB和缓存的数据不一致。
另外一个相对优雅一点的做法是,缓存中不仅仅缓存需要的key值(假定为:key1)之外,额外设定一个标识是否需要重新重建缓存的key值(假定为:key2), key1的过期时间一定大于key2的过期时间,所以当读取key1的时候,检查key2是否存在,不存在的话,则将key1加到重建队列中,重建缓存。 这样最终的效果是 真正的数据提供的key1相当于永远不失效,且尽可能的减少了数据不一致的情况。
上面两种,比较倾向于第一种,代码上相对简介,维护起来也简单些,但如果数并发要求很高的话,第二种可能更合适些。因为第二种,基本可以保证数据可以完全命中,而第一种则可能会出现等待的情况。
3、随机设定过期时间
缓存击穿的另外一种场景是,缓存中大批量的key值同时过期失效,所以导致大量请求回DB请求,导致DB压力变大。这种情况的处理方式也可以使用上面两种。还可以使用一种方案是,随机设定key值的过期时间,一定程度上可以防止缓存同时过期的情况。但这种业务上相对不太友好。
PS:缓存穿透和缓存击穿的区别
缓存穿透和缓存击穿这两者,都有个点是在于,缓存中查询不到数据,转而去请求DB层的数据,所以两者都会导致DB的压力变大。
但区别在于, 缓存穿透更关注的点在 数据本身在DB中不存在,所以,即使回源查询DB,缓存依旧无法查询到。 而缓存击穿则更侧重于,数据本身DB中存在,但缓存存在过期时间,过期导致缓存不命中而对DB产生的请求。
所以,从上面的解决方案来看,两者的解决方案侧重点也不一样。
缓存雪崩
缓存雪崩比较常见的两种情况:
1、某节点导致缓存雪崩
之前有写过一致性哈希,具体可以看《》,里面提到一种做法是,为了分散压力,可以使用多台redis机器组成一个集群,但有种场景是,如果某台机器宕机,为了保证业务,宕机机器上的流量和数据需要迁移到其余几台机器上,但如果其余几台机器也扛不住压力,就可能会出现又一台机器宕机,紧接着随着机器的减少,整个缓存集群都会出现宕机的情况。 也就是缓存雪崩了。
2、缓存宕机之后,导致DB宕机
缓存宕机后,缓存中查询不到,便会到后端DB上查询,一般情况下,加缓存的目的是为了减少DB的压力,或者说DB在当时的业务场景下已经是瓶颈,所以才需要加缓存缓解DB压力。 但因为缓存的宕机,导致大量请求打到DB上,也会导致DB瞬间宕机。 进而导致系统雪崩。
同样,因为DB宕机了,依赖此业务的服务也会跟着出现吞吐下降的情况,进而导致整个系统出现雪崩。
解决:
系统中增加降级熔断机制,有开源的类库可以使用,比如阿里的Sentinel, Netfilix的Hystrix都可以做到。
如果达到系统瓶颈时,直接快速失败,切断对后端服务(DB)的请求,等待系统恢复后,再请求相关服务。 这样可以做到保护系统。
